SDWebUI体验
-
配置:macbook m1
1. 环境配置
-
安装homebrew(安装包管理器)国内镜像:
/bin/zsh -c "$(curl -fsSL https://gitee.com/cunkai/HomebrewCN/raw/master/Homebrew.sh)" - 终端使用homebrew安装各种工具(已安装的可以忽略):
brew install cmake protobuf rust python@3.10 git wget - 前两步完成后运行SD Web UI的环境已经配置好了,git AUTOMATIC1111开发的SDwebUI项目代码到本地
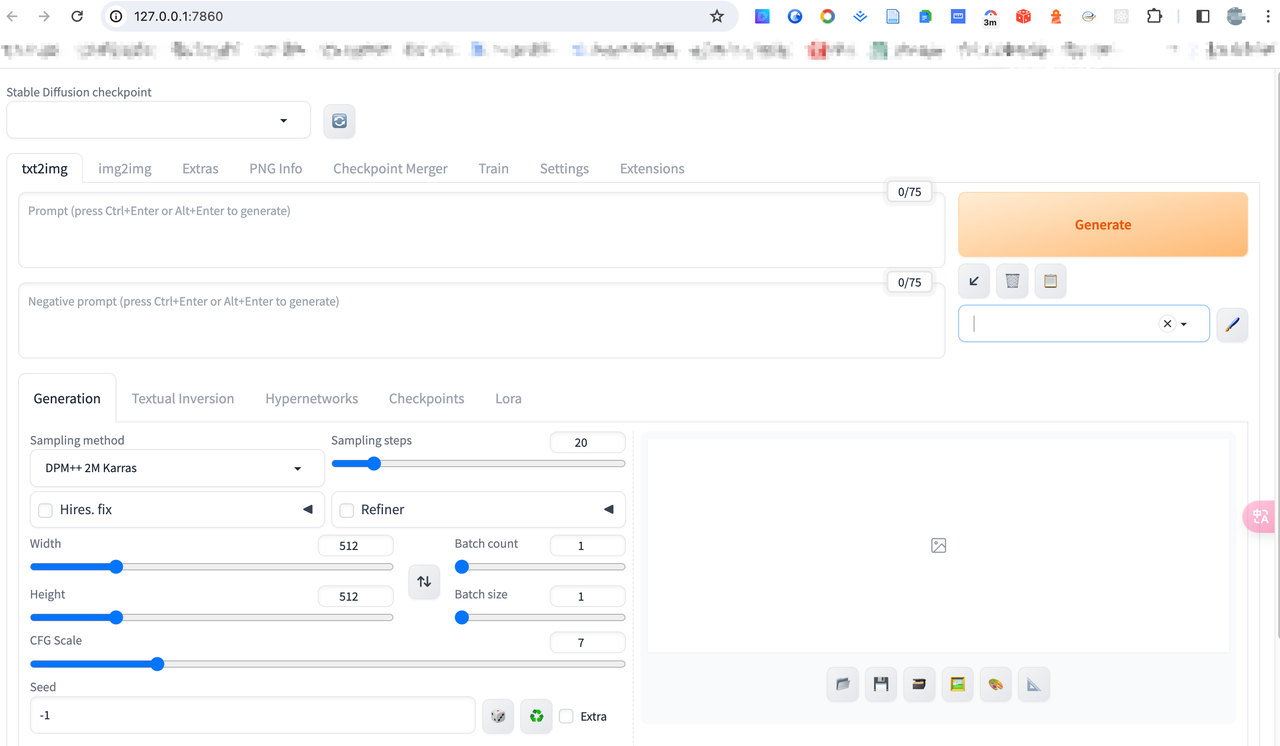
- 打开stable diffusion项目代码找到webUI.sh脚本用终端打开运行,脚本自动帮你下载项目依赖,下载成功后自动打开浏览器展示页面(如图1)。

图片中stable diffusion model failed to load是因为初始项目model文件夹为空,因此无法加载模型,可在ai大模型素材网站civitai和hugging face手动下载想要到模型到models文件夹即可。
- 打开浏览器,看到web ui就成功了,开始作图吧~
2. Modal下载
共享模型和数据集的平台有:
- hugging face:类似github,具有成熟的模型社区和评论互动。
- civitai:类似pinterest一样的图片瀑布流性,直观展示每个模型的视觉风格,更利于搜索。
💡: 本文模型素材皆来自civitai(下文简称c站)。
2.1 什么是Base Model模型
在c站几乎所有模型中的base model一栏通常会是SD1、SD1.5等底模型,这是SD官方发行的图片生成模型,具有大而全的特点。但正因为训练数据全而不精,导致仅使用底模生成的图片质量不佳,难以满足需求。因此“炼丹师”会在底模的基础上继续投入大量高质量特定风格的图片继续训练,形成针对性更强、画面更精美的模型,包括checkpoint、embedding和LoRA三种形态。
2.2 什么是checkpoint-embedding-LoRA
checkpoint、embedding、LoRA这三种模型都可以显著提升图片的风格特性,使用方法类似但原理有所差别。
2.2.1 checkpoint 检查点模型
底模也是一种checkpoint。但因为产出取决于训练数据,想要更新产出,就需要更新训练数据,因此更多“炼丹师”在底模基础上(巨人肩膀上)继续投入新的风格图片并将训练结果记录下来形成新的模型。因此check体积较大,通常在2-8GB内。使用checkpoint可生成比底模质量更好,视觉风格更一致的图片。
- 使用方法:下载checkpoint放到stable diffusion webUI-> models -> stable diffusion文件夹内即可。
2.2.2 embedding 文本嵌入
在生成图片时,除了选定模型外,还需要大量精确的描述词帮助模型理解你的需求。有没有可能有人已经帮你写好了prompt词?embedding就是如此。embedding使用向量文本更加精确定位图像特征,让模型更具针对性。就好比某次语文考试范围是一整本书,A学生拿到了一张小抄,上面透露了本次考试的更精确的范围是第5章,Ta将精力都放在复习第五章内,因为Ta得到了更加聚焦的消息,因此考出了更高的分数。embedding格式是纯文本,因此体积仅占几十KB。
- 使用方式:下载embedding放置到stable diffusion webUI-> embeddings 文件夹,在正向Prompt词输入框内填写触发词
trigger words即可,根据embedding作者提示还可调整模型权重调节画面效果。2.2.3 LoRA(Low-Rank Adaptation Models) 低序适应性模型。
LoRA像是一种外挂,用于调节checkpoint产出。embedding只是给出了更精确的定位,但无法告知更新的知识。LoRA则是对某个人物或某种风格更新、更详细、更具体的训练模型。就好比B同学在语文考试前拿到了一张新闻报纸,与没有报纸的其他同学相比,B同学阅读到的相关新闻素材指导他写出了更震撼人心的文章,最后考出了非凡的成绩。因此LoRA是面向某种checkpoint新的延伸,信息量比embedding大,但比checkpoint小,体积约占数百MB。
- 使用方式:下载LoRA放置到stable diffusion webUI-> models -> LoRA文件夹,在正向Prompt词输入框内填写
<lora:${lora模型名称}>即可触发。
2.3 常用模型
大量“炼丹师”的辛勤劳作促进模型社区的不断发展,许多模型经历了多次升级,下面整理常见风格的模型,模型名称随着迭代可能会有所不同。
💡 当前AI在视觉效果方面遥遥领先,但在图像逻辑处表现不佳,具体表现在如文字、尺寸等地方毫无逻辑,这与图像生成原理有关。因此在海报设计、icon设计、界面设计方面不建议使用AIGC。
2.3.1 二次元模型
-
搜索关键词:Illustration, painting, sketch, drawing, comic, anime, catoon
-
模型推荐:
-
Anything 万象熔炉 (日漫)
- Counterfeit V2.5 (日漫)
- Dreamlike Diffusion(梦幻、赛博)
-
2.3.2 写实派模型
- 搜索关键词:Photography, photo, realistic, photorealistic, RAW photo
- 模型推荐:
- Realistic Stock Photo
- Realistic Vision
- Realistic Stock Photo
2.3.3 Q版真人模型
-
搜索关键词:3D, render, chibi, digital art, concept art
- 模型推荐:
- Q版风格 CHIBI
- Never Ending Dream (NED)
- Protogen(Realistic)
- 国风(GuoFeng3)
2.3.4 产品设计
- Q版风格 CHIBI
- 搜索关键词:product design
- 模型推荐:
- Product Design (Realistic minimalism-eddiemauro)
- Product Design (Tech minimalism-eddiemauro) LORA
- Product Design (Realistic minimalism-eddiemauro)
2.3.5 UI设计
- 模型推荐:
- APP ICONS - SDXL
- APP ICONS - SDXL
2.3.6 建筑设计
- 模型推荐:
- architecture_Exterior_SDlife_Chiasedamme
2.3.7 海报设计
- architecture_Exterior_SDlife_Chiasedamme
- 模型推荐
- Movie Poster (文字部分可看出毫无逻辑😰)
- Movie Poster (文字部分可看出毫无逻辑😰)
2.3.8 风格插画
- 模型推荐:
- SDVN7-NijiStyleXL (绝美的一个风格)
- SDVN7-NijiStyleXL (绝美的一个风格)
3. 图片生成初体验
- 选用模型:Realistic vision
- 参数调节:选定某张图片后,可抄目标图片右侧参数作业。
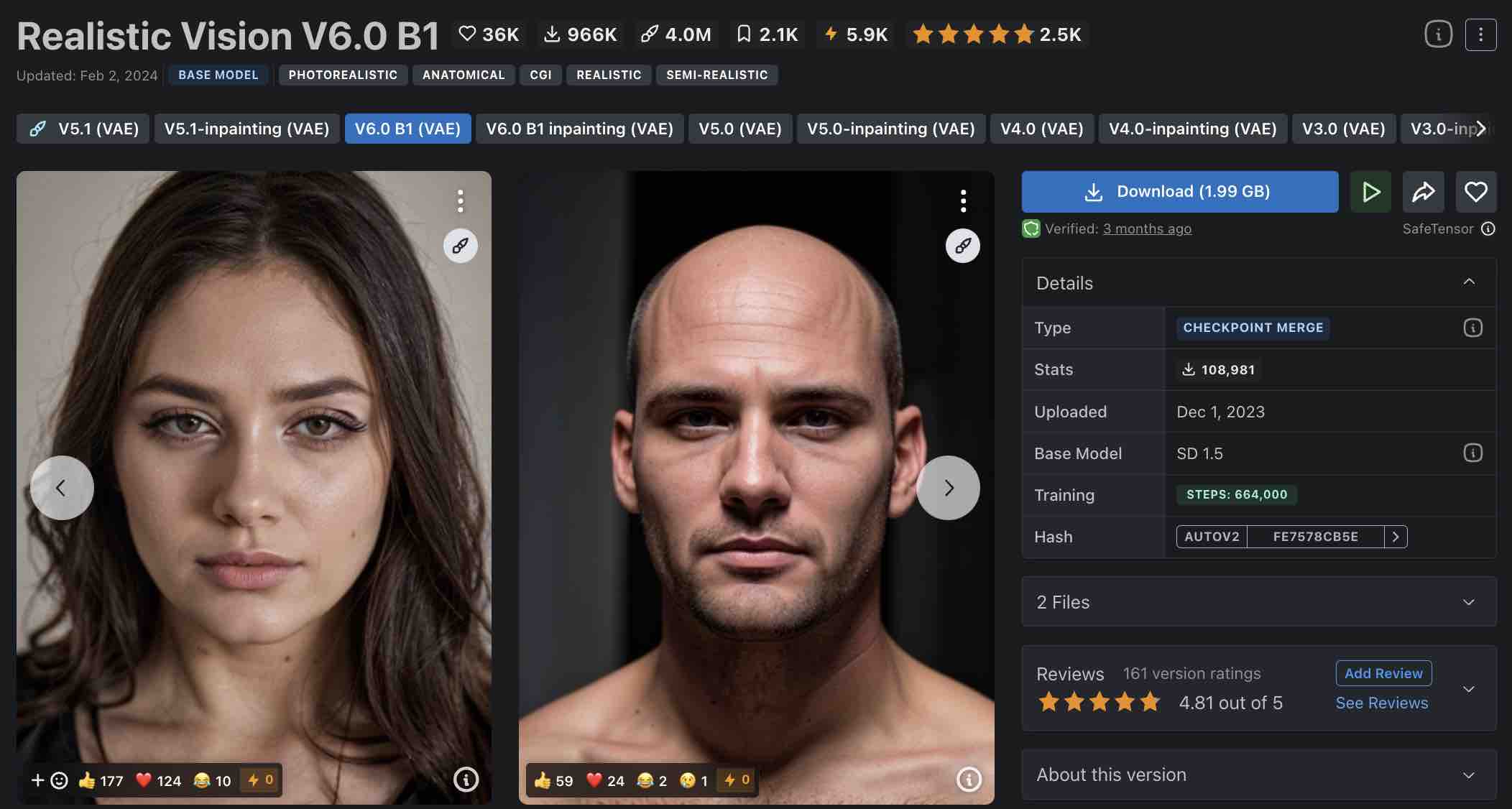
第一次出图:
prompt:closeup portrait photo of beautiful 26 y.o woman, makeup, 8k uhd, high quality, dramatic, cinematic
Negative prompt:(deformed iris, deformed pupils, semi-realistic, cgi, 3d, render, sketch, cartoon, drawing, anime), text, cropped, out of frame, worst quality, low quality, jpeg artifacts, ugly, duplicate, morbid, mutilated, extra fingers, mutated hands, poorly drawn hands, poorly drawn face, mutation, deformed, blurry, dehydrated, bad anatomy, bad proportions, extra limbs, cloned face, disfigured, gross proportions, malformed limbs, missing arms, missing legs, extra arms, extra legs, fused fingers, too many fingers, long neck
seed:3108443162 (seed种子,可看作某张图片内容风格的坐标,沿用参考图片的seed可生成类似的图像内容,若选择任意seed,生成图像内容自由度增更高。)
耗时:56sec
出图大小:512*512;329kb
成品:

存在的问题:皮肤模糊,高光太虚,画质不高。 改进方式:使用hires.fix高清修复功能,调高scale为1.4,步数为10,denoising strength为0.5。
第二张图
耗时:61sec
出图大小:512*512;632kb
成品:

结论:画质确实清晰了一倍,达到632kb,但seed变成随意后美女完全变了。增加sampling steps作用不大,但增加scale作用显著。另外,把图一直放着,就会根据这个图不断生成。保留该张图片的seed重新制作第三张。
第三张图
耗时:73sec
出图大小:512*512;1.2M
成品:

结论:将scale调为2,画质已经没有明显变化,但图片体积仍然翻倍。保留seed后美女似乎保持了同一个人,但仔细观察头发、眼睛却有了细微变化。为了增加真实感,增加斑点、高光high light on skin, two small molesprompt词制作第四张图。
第四张图
耗时:75sec
出图大小:512*512;1.2M
成品:

结论:由于prompt词的改变,每次又变脸了,但大模型似乎没有听懂我的色素痣moles,美女脸上依旧白皙无暇,后面出图也发现,并不能完全依赖输入词来决定图像内容。
—
4. 小结
对比使用纸笔或ipad画画,ai作图成就感极低且不确定性极高,加上电脑配置不足导致出图时长过长,刚开始的新鲜感已被消耗殆尽。我在翻看c站模型时,发现这些看似精美的图片并没有像pinterest、behance、dribbble的作品一样让人眼前一亮。这些精美图片的出路在哪里?AIGC图片具有完美的但意料之中的视觉效果,但太过完美极易导致视觉疲劳。想要增加图像的吸引度,可增加图像的故事性、逻辑性、娱乐性、新颖性。例如创作具有故事性的连环画、创作不寻常的图片等,令图像具备超脱像素的信息量。下一集的目标将是制作一则连环画或是一则海龟汤~
未完待续……